· Vojtech Svoboda · Observabilita · 6 min čtení
Jak na metriky z Azure služeb
Jak exportovat a vizualizovat metriky z Azure služeb a obejít omezení Azure portálu
Export metrik z Azure a jejich vizualizace
Když jsem se poprvé snažil získat 3 měsíční pohled na metriky Azure, myslel jsem si, že se jedná o jednoduchý úkol. Prostě stačí v portálu natáhnout časovou osu grafu. Spoiler: nestačí.
Azure umožňuje v jednom grafu zobrazit maximálně 30 dní dat (je to z důvodů výkonu stránek). A co hůř — ve výchozím nastavení uchovává pouze 93 dní (pokud metriky neposíláte do Log Analytics Workspace).
Takže pokud chcete souvislý graf přes tři měsíce, nemůžete jen tak “odscrollovat zpět”. Musíte metriky exportovat, pospojovat a vytvořit vlastní vizualizaci. Přesně to jsem udělal — a tady je jak.
Omezení Azure
Nejdřív bych chtěl stručně shrnout, co Azure umí a neumí, než se pustím do popsání celého postupu.
- Doba uchování: Azure uchovává metriky ve výchozím nastavení 93 dní.
- Grafy v portálu: V grafu lze zobrazit maximálně 30 dní dlouhý interval.
- Export přes CLI: Přes Azure CLI lze na jeden dotaz vyexportovat také maximálně 30 dní.
Z toho plyne, že jakýkoli požadavek na graf, zobrazující časové období delší než měsíc, vyžaduje export metrik a práci s nimi mimo Azure (datové agregace). Jakmile to víte, celý proces se změní na pipeline “stáhni, zpracuj, vizualizuj”.
Práce s Azure CLI
Prvním krokem je dostat data z Azure ven. Azure CLI je jednoduchý a flexibilní nástroj — je snadno skriptovatelný, multiplatformní a ideální pro automatizaci (alternativou by bylou použití Azure API). Abych obešel limit 30 dnů na dotaz, opakuji příkaz v cyklu pro celé požadované období. V každé iteraci upravuji start_time a end_time tak, abych sekvenčně exportoval 30denní úseky, dokud nezískám kompletní dataset pro požadovaný časový rámec.
Základní příkaz vypadá takto:
az monitor metrics list \
--resource "$resource_id" \
--metric "$metric_name" \
--start-time "$start_time" \
--end-time "$end_time" \
--interval PT1H \
--aggregation Total \
--output json > "$output_file"Podrobné informace k tomuto příkazu jsou v dokumentaci Azure.
Vysvětlení proměnných parametrů
Pojďme si nyní vysvětlit nejdůležitější parametry příkazu:
resource_id– Azure Resource ID v plném formátu. Příklad:/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myResourceGroup/providers/Microsoft.ContainerService/managedClusters/myClustermetric_name– Název metriky, kterou chcete exportovat (např.node_network_in_bytes). Každá služba Azure nabízí jiné metriky.start_time/end_time– Časový rozsah ve formátuYYYY-MM-DDThh:mm:ssZ. Maximum: 30 dní na jeden dotaz.interval– Zde nastaveno na hodinový (PT1H), ale můžete přizpůsobit podle potřeby. Pro více podrobností se podívejte na dokumentaci Azure o agregaci metrik.Formát výstupu – Používám JSON, protože se s ním dobře pracuje v kódu, ale Azure podporuje více formátů.
Jak vypadá výstup
Po spuštění příkazu Azure vrátí JSON dokument s poměrně komplexní strukturou. Obsahuje metadata, časové intervaly a vlastní hodnoty metrik.
Zkrácený příklad vypadá takto:
{
"interval": "PT1H",
"timespan": "2025-04-16T00:00:00Z/2025-05-15T23:59:59Z",
"value": [
{
"displayDescription": "Network received bytes",
"timeseries": [
{
"data": [
{ "timeStamp": "2025-04-16T00:00:00Z", "total": 11986356390.0 },
...
{ "timeStamp": "2025-04-16T01:00:00Z", "total": 8171367295.0 }
]
}
],
"unit": "Bytes"
}
]
}Pro nás je nejdůležitější přístup k datům, které jsou v následující JSONPath:
.value[].timeseries[].data[]Tam se podíváme dál.
Další krok - vizualizace
Jakmile máme základní dataset, můžeme otevřít Excel a pracovat v něm. Ale JSON (nebo i CSV) je těžko čitelný formát pro člověka (nebo i Excel) a datech se špatně hledají klíčové trendy.
Dobrý graf z těchto čísel udělá něco intuitivního. Snadno vidíte peaky, trendy a anomálie. Proto je dalším krokem vykreslení dat v Pythonu.
Zpracování dat v Pythonu
Než něco vykreslíme, je potřeba vytáhnout relevantní data z JSONu a zjednodušit je pro další práci. Postupoval jsem takto:
with open(json_file, 'r') as f:
data = json.load(f)
metrics_data = []
for datapoint in data['value'][0]['timeseries'][0]['data']:
if 'timeStamp' in datapoint:
timestamp = datetime.fromisoformat(
datapoint['timeStamp'].replace('Z', '+00:00'))
value = datapoint.get('total')
# Convert bytes to GiB
value_gb = value / (1024**3)
metrics_data.append({
'timestamp': timestamp,
'value': float(value),
'value_gb': float(value_gb)
})Z mého pohledu:
- Načítám JSON soubor pomocí Pythonu.
- Procházím každý datový bod.
- Převádím hodnoty z bajtů na gibibajty (protože pracovat s miliardami není příliš uživatelsky přívětivé).
- Výsledky ukládám do jednoduchého seznamu slovníků (ano, čeština se zde nepotkává s terminologií programátorů, chápejme tedy List of Dictionaries).
Vykreslení dat
Se strukturovanými daty je vykreslení jednoduché. Pro práci s daty jsem využil knihovny Pandas a matplotlib, které jsou v Python komunitě široce používané. Pandas usnadní třídění a organizaci dat, Matplotlib vykreslování do grafu.
Následující úryvky kódu jsou součástí Python skriptu, který jsem použil, ale pojďme si je rozložit pro lepší pochopení procesu.
V prvním úryvku vytvářím samotný graf. Poté načtu data do Pandas DataFrames, primárně pro jednodušší manipulaci s daty. V tomto příkladu data moc neupravuji, pouze je řadím podle časového razítka (timestamp) pro případ, že by mi Azure poslal neseřazený seznam. Pokud bych však chtěl kombinovat více časových období dat dohromady, nebo provádět jinou manipulaci s daty, DataFrames by mi úkol značně usnadnily.
Více informací o těchto knihovnách najdete v dokumentaci Matplotlib a dokumentaci Pandas.
# Named imports
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Create figure
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
# Set title
fig.suptitle("Metrics graph", fontsize=16, fontweight='bold', y=0.95)
# Get data into dataframes and sort them
df = pd.DataFrame(metrics_data)
df = df.sort_values('timestamp')
# Plot line
ax.plot(df['timestamp'], df['value_gb'],
color='#1f77b4',
linewidth=2,
alpha=0.9)
V této chvíli mám čistou křivku se stínováním — pro člověka mnohem čitelnější a více vypovídající než JSON.
Jak si graf vylepšit
Dobrý graf není jen o čáře — jde o to, aby byly detaily jasné bez zahlcení. Tato část kódu nastavuje jednotlivé části grafu. Vypíchnul bych zde nastavení osy X, kde kód přizpůsobuje popisky os rozsahu dat, aby se datumy nehromadily a zůstaly čitelné.
# Add subtle fill under the line
ax.fill_between(df['timestamp'], df['value_gb'],
alpha=alpha_fill, color=fill_color)
# Clean, minimal styling
ax.set_xlabel('Time', fontsize=11)
ax.set_ylabel('Network Traffic (GB)', fontsize=11)
# Minimal grid
ax.grid(True, alpha=0.3, linestyle='-', linewidth=0.5)
ax.set_axisbelow(True)
# Format x-axis - adaptive based on data range
date_range = (df['timestamp'].max() - df['timestamp'].min()).days
if date_range <= 7: # Week or less - daily ticks
ax.xaxis.set_major_locator(mdates.DayLocator(interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
elif date_range <= 31: # Month or less - every few days
ax.xaxis.set_major_locator(mdates.DayLocator(interval=3))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
else: # Longer periods - weekly
ax.xaxis.set_major_locator(mdates.WeekdayLocator(interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
plt.setp(ax.xaxis.get_majorticklabels(),
rotation=45, fontsize=9, ha='right')
# Clean background
ax.set_facecolor('#ffffff')
# Plot padding adjustments
plt.tight_layout()
plt.subplots_adjust(top=0.9, bottom=0.15)Uložení grafu
Jakmile jsme spokojení s výsledkem, uložíme graf jako PNG pro sdílení, reporty nebo archív.
output_file = os.path.join(output_dir, 'my_awesome_graph.png')
plt.savefig(output_file, dpi=300, bbox_inches='tight', facecolor='white')
plt.close()Výsledek
Výsledný graf může vypadat například takto: 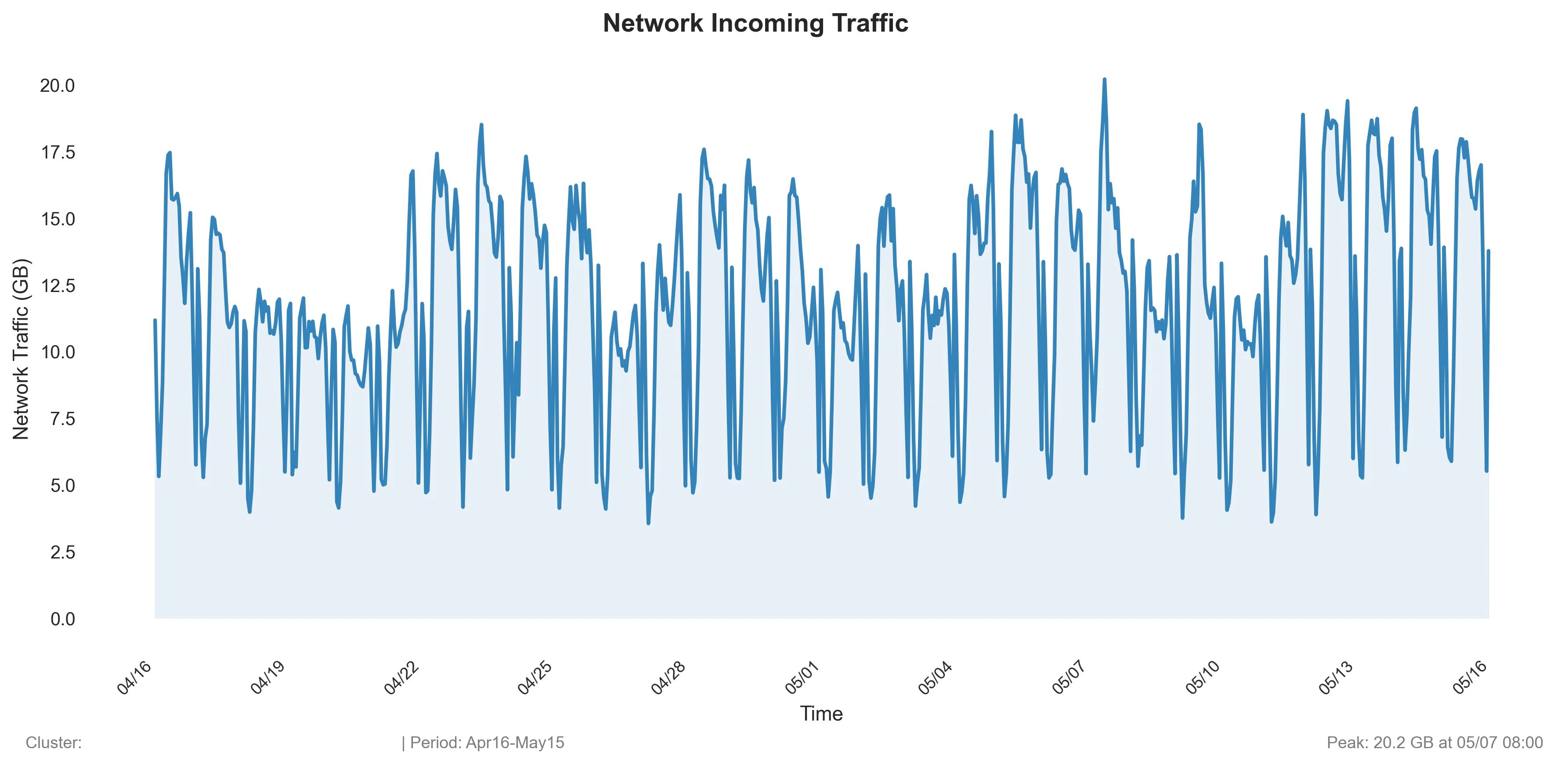
Závěrem
Tento postup není nejrychlejší — musíte exportovat, transformovat a vizualizovat — ale nabízí skvělou kontrolu (a pro mě osobně je mnohem rychlejší, než práce v Excelu).
Už nejsme svázáni 30denním oknem Azure. Můžeme vidět větší perspektivu, když poskládáme data z více měsíců, a grafy si přizpůsobíme podle sebe.
A upřímně, je dost uspokojující vzít JSON z Azure a proměnit ho v pěknou a přehlednou vizualizaci.